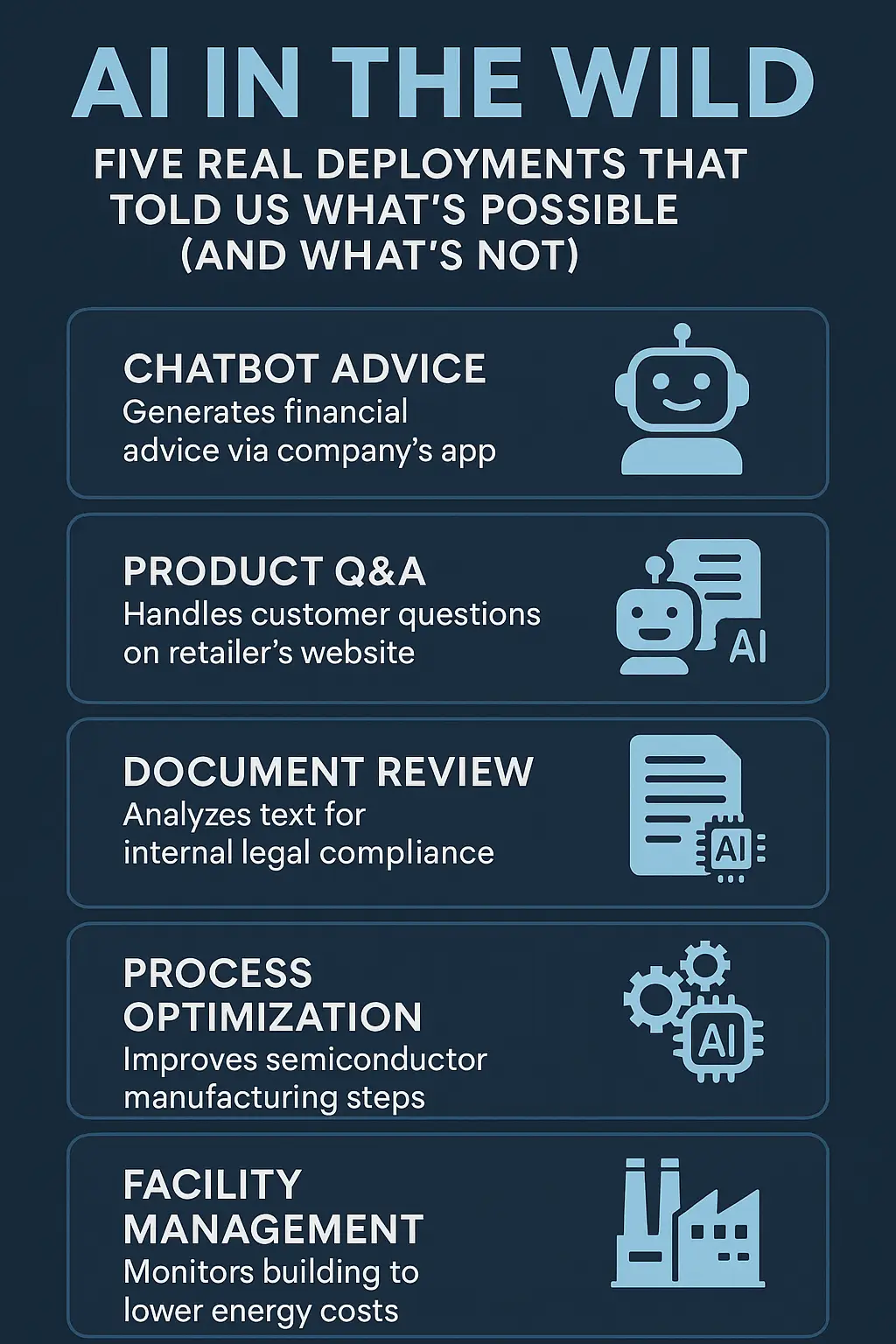
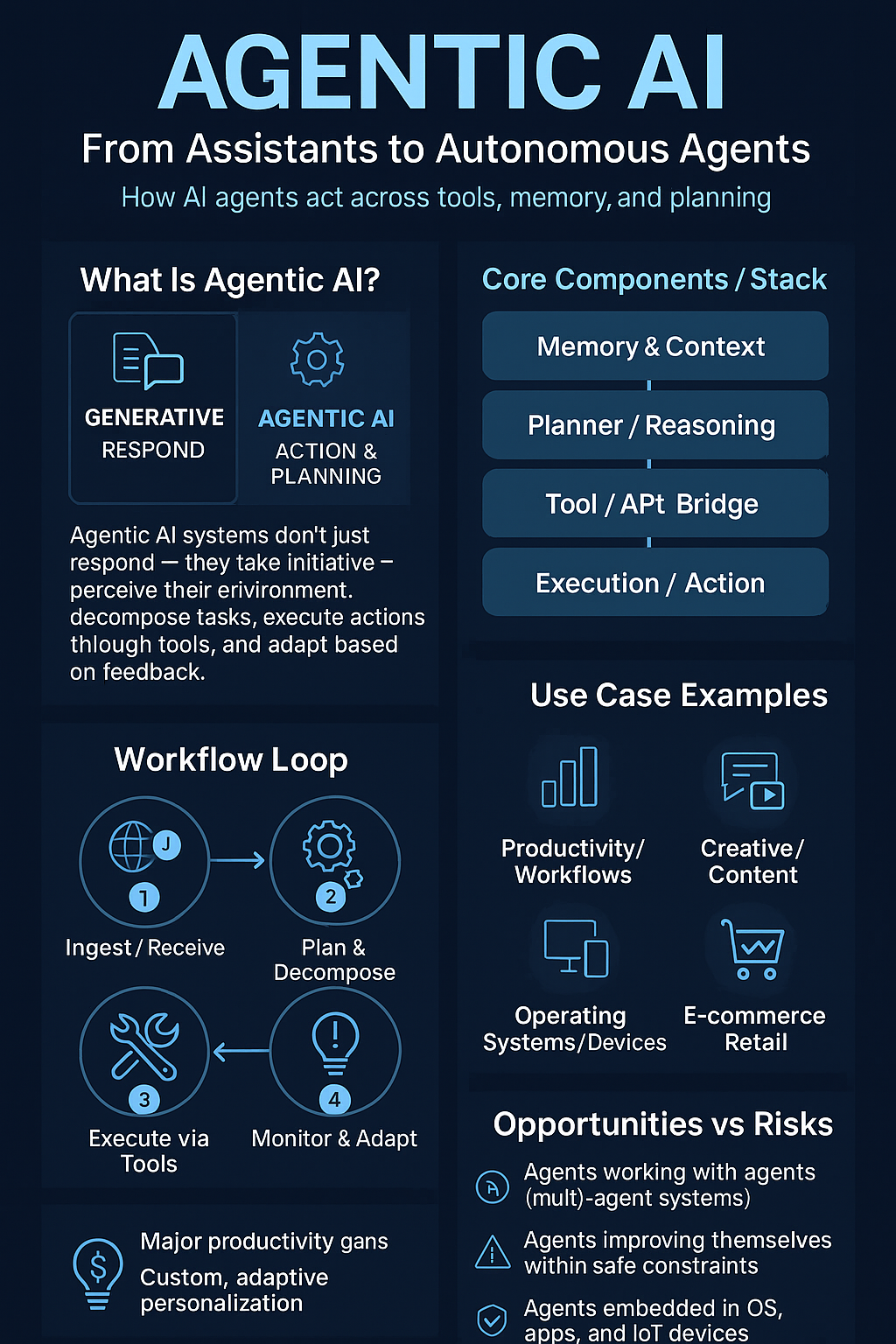
Claude Sonnet 4.5 vs GPT-5 vs Qwen3-Max: The 2025 AI Model Showdown
The race for AI dominance has entered a new phase. Anthropic’s Claude Sonnet 4.5, OpenAI’s GPT-5, and Alibaba’s Qwen3-Max are competing not just on intelligence — but on reasoning, scale, and autonomy. Here’s how they stack up.
📊 Head-to-Head Comparison
| Criterion | Claude Sonnet 4.5 | GPT-5 | Qwen3-Max |
|---|---|---|---|
| Release | Sept 2025 | Mid-2025 | Sept 2025 |
| Core Strength | Long-horizon reasoning, SWE-Bench leader, agentic execution | Balanced multimodal AI, ecosystem integrations, safety-first | Scale (1T+ parameters), code + enterprise tasks |
| Benchmarks | Record-breaking SWE-Bench (software engineering) | Competitive across MMLU, multimodal, reasoning | Strong in coding and agent simulations |
| Autonomy | Sustains 30+ hrs of reasoning workflows | Strong but often tied to external frameworks | Marketed as agent-ready |
| Accessibility | Select partner + Claude.ai users | Widely integrated in ChatGPT ecosystem | Primarily via Alibaba Cloud |
| Trade-offs | Compute intensive, generalization edge cases | Safe but sometimes less agentic | Costly inference, sustainability issues |
⚖️ Pros & Cons
Claude Sonnet 4.5
✅ Best-in-class reasoning
✅ Sustains long workflows
❌ Still limited access
❌ Expensive to run
GPT-5
✅ Broad ecosystem + multimodal
✅ Stable and safety-oriented
❌ May underperform on ultra-long reasoning
❌ Some features still gated
Qwen3-Max
✅ Scale and ambition unmatched
✅ Asia-centric integration advantage
❌ Huge compute footprint
❌ Unproven beyond benchmarks
🎯 Who Should Use Which?
-
Claude Sonnet 4.5 → For developers, coders, and researchers building agentic workflows.
-
GPT-5 → For enterprises needing stable, versatile, multimodal AI with broad integration.
-
Qwen3-Max → For organizations in Asia or those testing ultra-large scale deployments.