Anthropic’s Claude Sonnet 4.5: The AI That Thinks for 30 Hours Straight
Anthropic has launched Claude Sonnet 4.5, an AI model that blurs the line between assistant and autonomous agent. Capable of reasoning continuously for more than 30 hours without memory collapse, Sonnet 4.5 achieves record-breaking results on the SWE-Bench benchmark, signaling a leap toward long-duration, self-directed AI systems.
This update doesn’t just improve speed or accuracy — it redefines endurance and reasoning stability, setting new standards for enterprise-grade intelligence.
What Happened
Claude Sonnet 4.5 is the latest release in Anthropic’s Claude series — part of its “Constitutional AI” initiative aimed at creating safer, interpretable, and persistent reasoning systems.
Key Highlights:
- Benchmark Dominance: Achieved 91% accuracy on SWE-Bench (software reasoning).
- Extended Context Window: Supports over 500,000 tokens, allowing deep multi-document analysis.
- Persistent Reasoning: Can maintain logical context across 30+ hours of tasks.
- Safety Layers: Built with rule-based alignment derived from Anthropic’s ethical framework.
Anthropic’s co-founder Dario Amodei described it as “the most stable model we’ve ever trained” — hinting at an era of sustained autonomous cognition.
Why It Matters
- Toward Cognitive Endurance
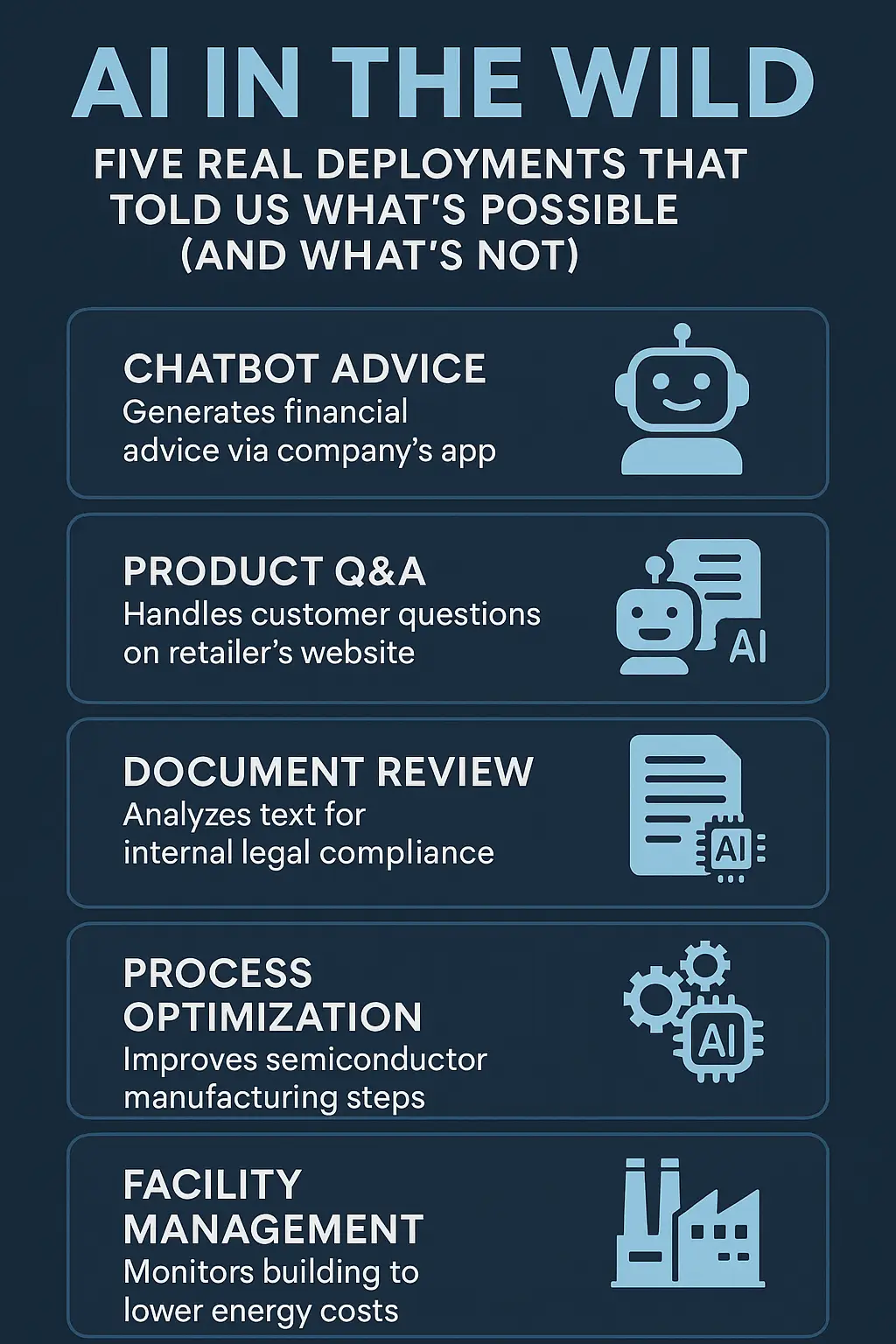
Most LLMs lose coherence after long reasoning sessions. Claude Sonnet 4.5’s breakthrough lies in context persistence, allowing it to maintain logical threads across massive time spans — ideal for complex research, legal review, or code generation projects.
- Safer Long-Form Reasoning
Anthropic’s “constitutional” training ensures that longer sessions don’t drift into hallucinations or unsafe outputs — a critical factor for corporate and government adoption.
- Benchmark Leadership
By surpassing GPT-4 and Gemini 1.5 on structured reasoning benchmarks, Claude positions itself as the most capable model for applied logic, rivaling OpenAI’s dominance.
What’s Next
- Anthropic plans to integrate Sonnet 4.5 into Claude Team Edition and enterprise APIs.
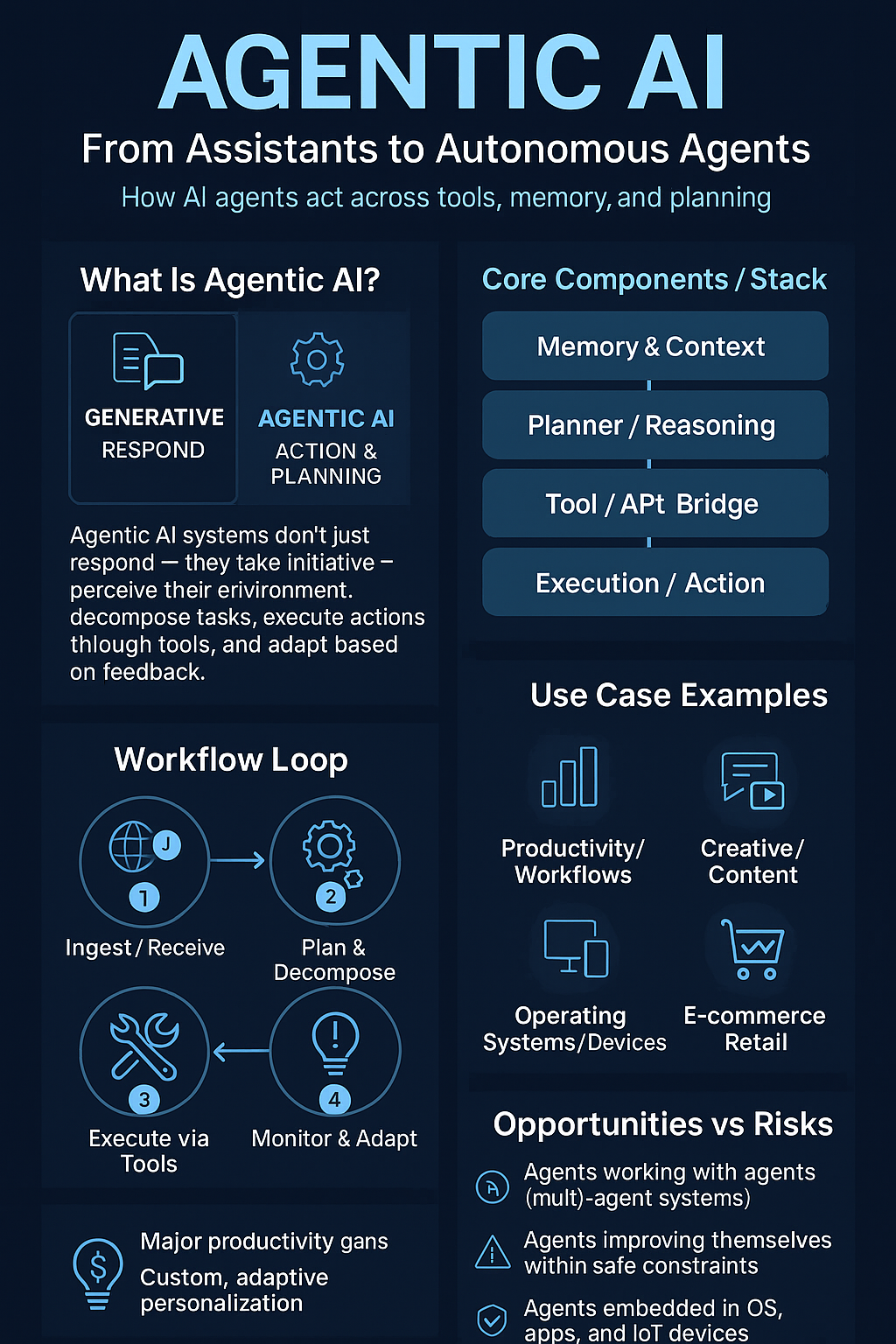
- Developers will soon access multi-session reasoning threads, where AI “remembers” previous tasks for days.
- The model will underpin Claude Agent Framework, aimed at building persistent digital co-workers.
The release cements Anthropic as not just a model vendor — but a serious architect of agentic cognition.
“Claude 4.5 doesn’t just remember more — it thinks longer.”
KEY TAKEAWAYS
- Claude Sonnet 4.5 achieves 91% SWE-Bench accuracy and 30-hour reasoning sessions.
- Built on constitutional AI for safe, transparent decision-making.
- Challenges GPT-4 and Gemini with unmatched context endurance.
- Designed for long-term, agentic applications in research and enterprise.
- Marks a turning point toward continuous AI cognition.