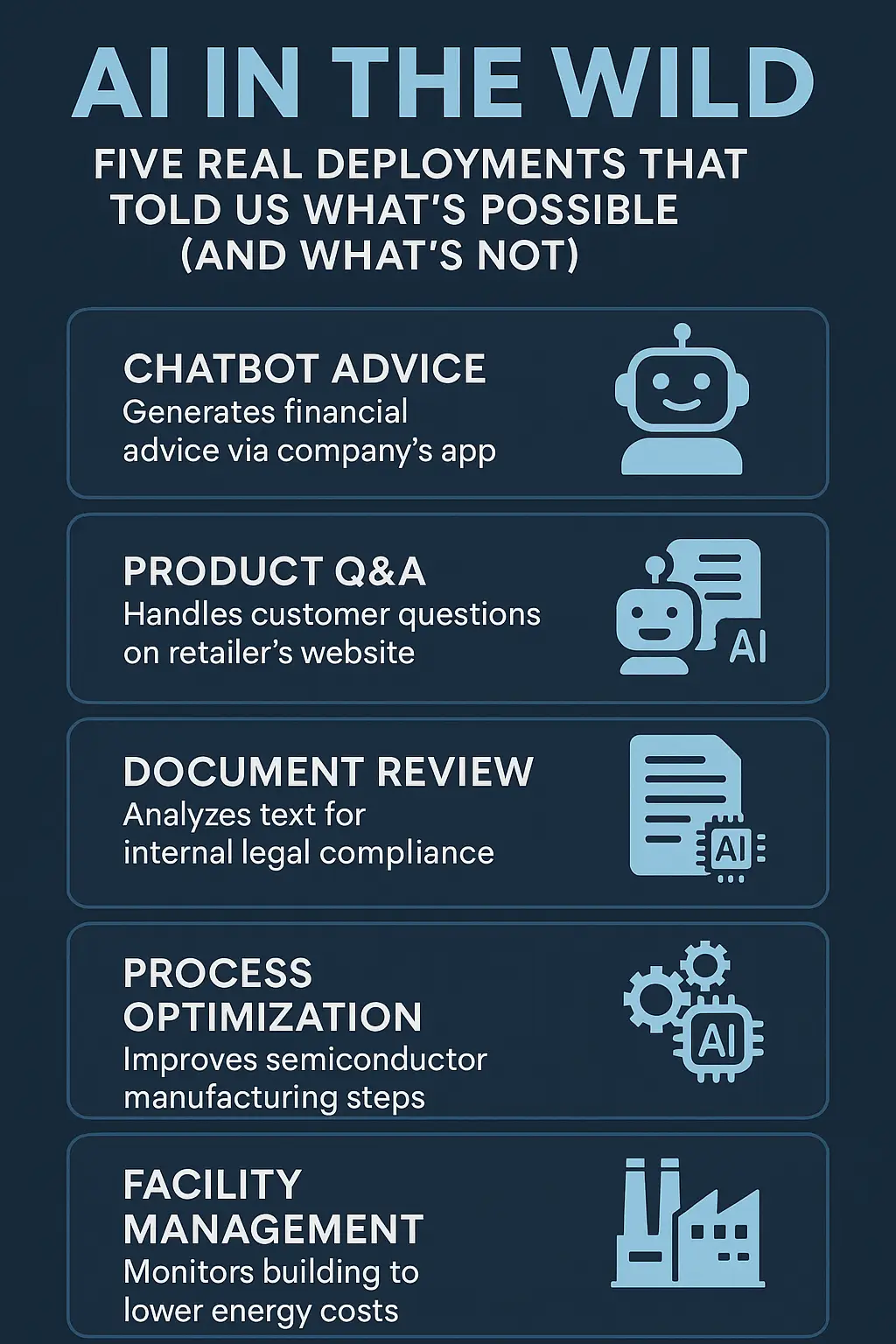
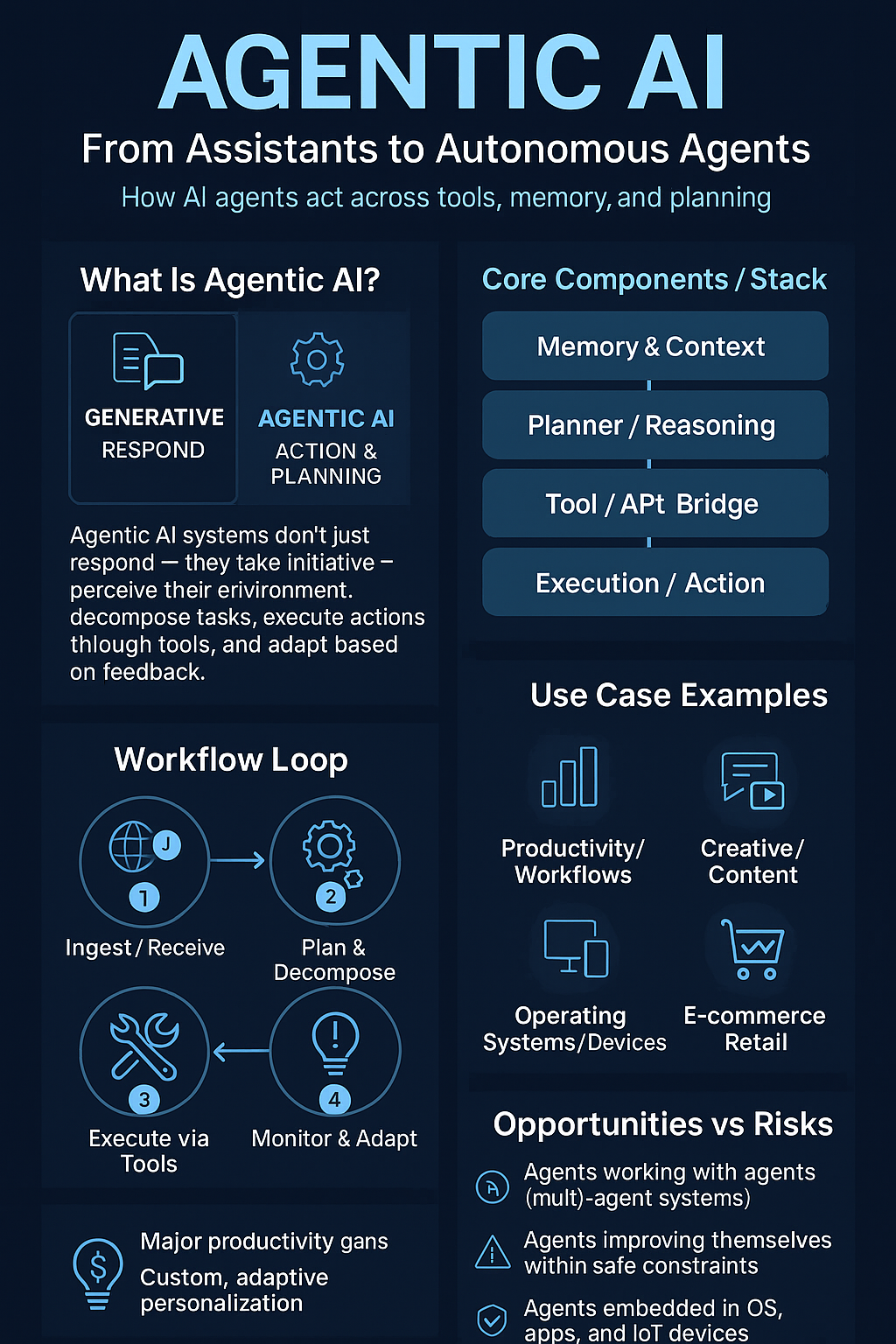
Anthropic Unveils Claude Sonnet 4.5 — A Leap Toward Truly Autonomous AI Agents
Anthropic has launched Claude Sonnet 4.5, positioning it as a step beyond traditional chat models. With record performance on SWE-Bench and the ability to sustain 30+ hours of continuous reasoning, Sonnet 4.5 signals a future where AI systems act more like autonomous agents than assistants.
What Happened
Claude Sonnet 4.5:
-
Achieved the highest-ever SWE-Bench score, a benchmark for software engineering.
-
Demonstrated continuous coding execution exceeding 30 hours.
-
Is designed to sustain complex reasoning and planning tasks.
Why It Matters
This isn’t just about being “smarter.” It’s about task orchestration. Sonnet 4.5 can plan, execute, debug, and adapt without constant human prompting — edging closer to agentic AI.
Future Implications
-
Developers may integrate Claude into IDEs and workflows, offloading entire coding cycles.
-
Competition will intensify: OpenAI’s GPT-5 and Google’s Gemini must respond.
-
Oversight challenges rise: an AI that can “do” also has greater potential to misfire without supervision.
👉 Takeaway: Claude Sonnet 4.5 represents a pivot in AI — from “conversation” to execution.