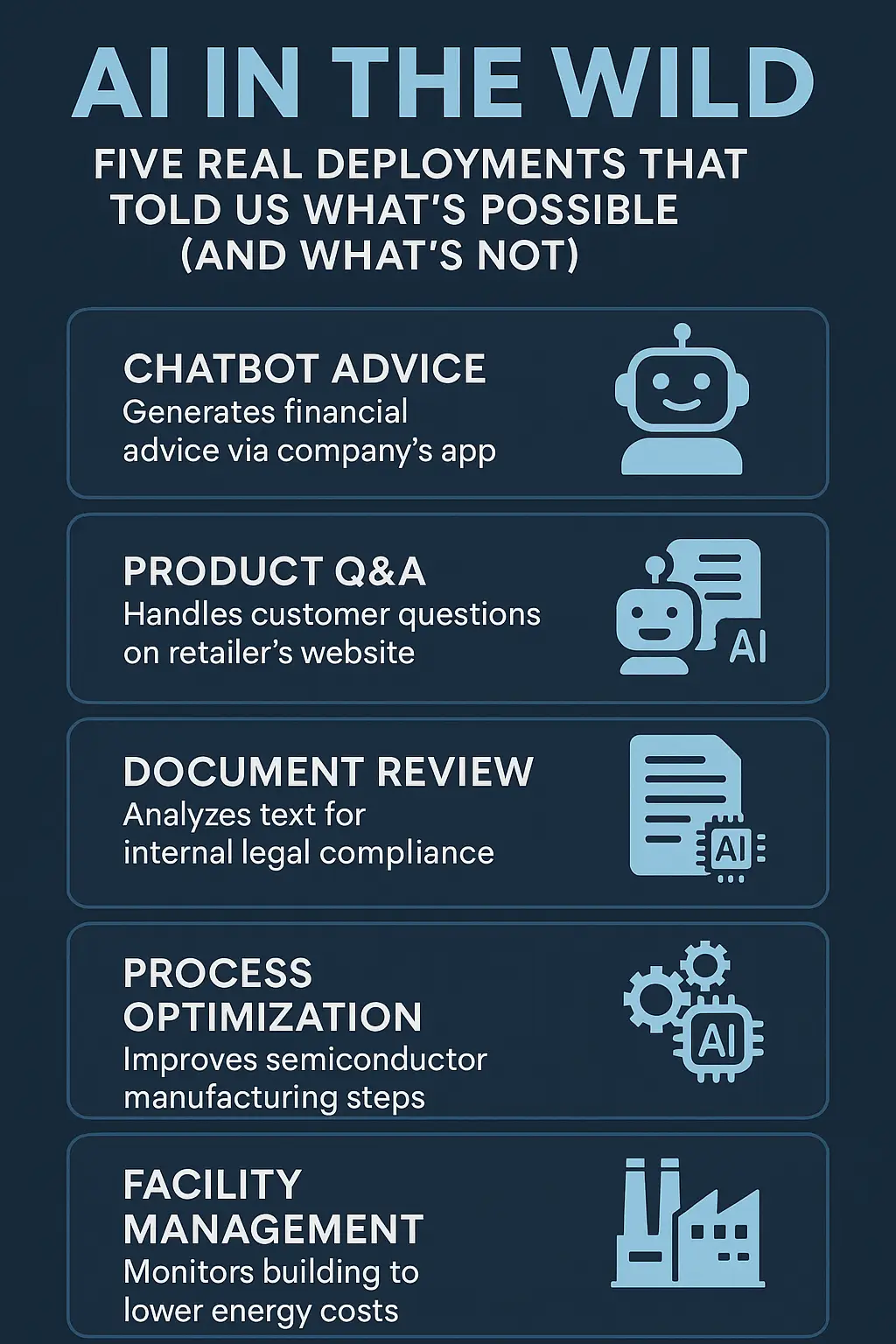
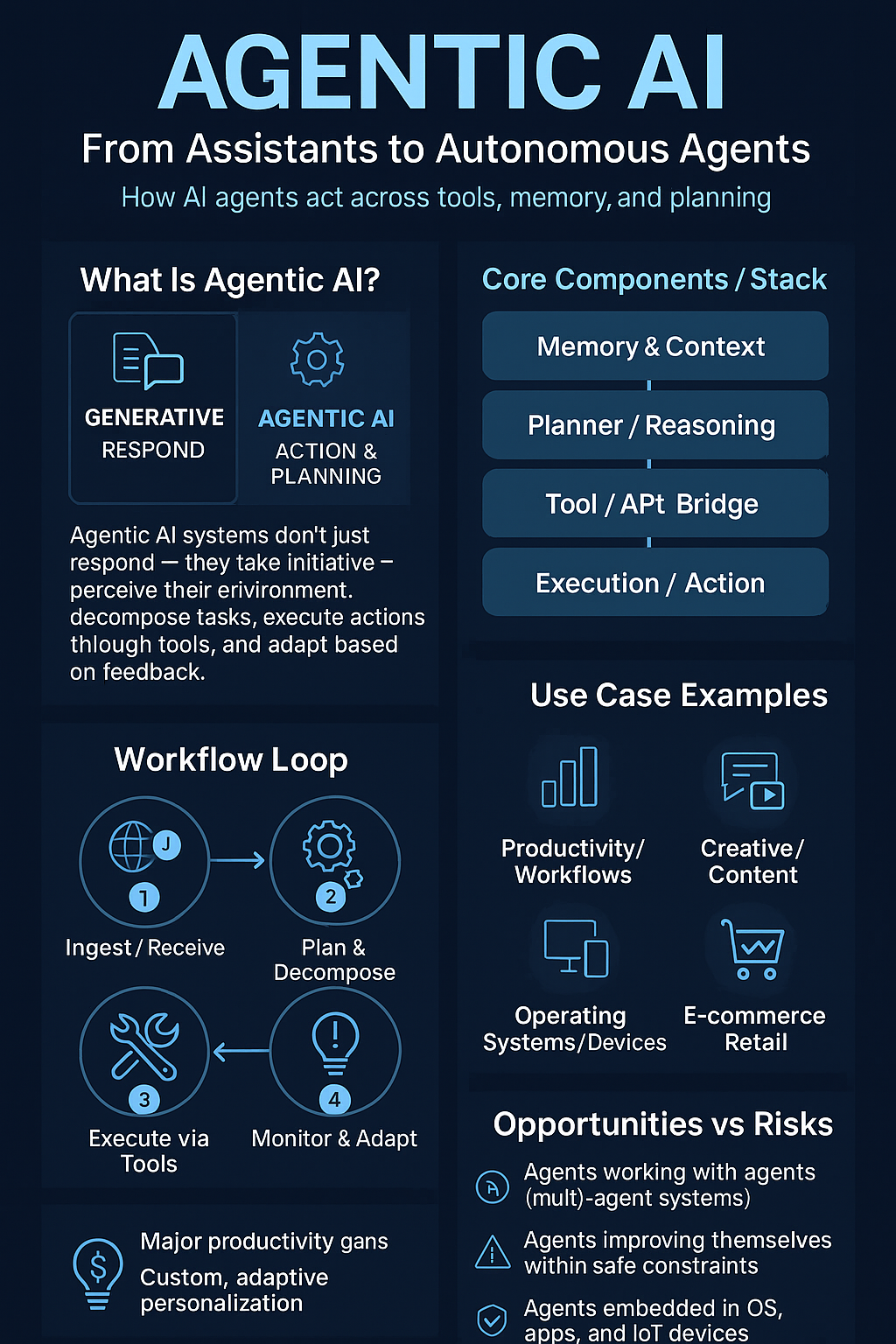
AI Benchmarks Are Broken — What Comes Next?
For years, AI progress has been measured through benchmarks like BLEU for translation or MMLU for reasoning. But in 2025, these tests are showing cracks. Models ace benchmarks but stumble in real-world use. The next era of AI evaluation needs to capture adaptability, reasoning, and autonomy.
 The Benchmark Problem
The Benchmark Problem
-
Overfitting to Tests → Models trained on benchmark datasets often “memorize” instead of generalize.
-
Narrow Scope → BLEU, ROUGE, and even MMLU measure narrow skills, not long-horizon reasoning.
-
Gaming the System → Companies optimize for benchmark bragging rights rather than real-world reliability.
-
Missing Agentic Context → Current benchmarks don’t test sustained workflows, planning, or tool usage.
The New Era of Evaluation
-
SWE-Bench → Tests AI on real-world software engineering problems (bug fixing, code patches).
-
GAICo → A unified evaluation framework for multimodal generative AI, enabling consistent cross-model comparison.
-
Task-Based Testing → Instead of multiple-choice, agents are judged on end-to-end task completion (e.g., writing + debugging code).
-
Human-in-the-Loop Evaluation → Crowdsourced or expert feedback adds realism to performance scoring.
Why It Matters
-
Enterprises need reliable benchmarks before adopting AI for mission-critical tasks.
-
Researchers require more holistic metrics to drive innovation beyond benchmark chasing.
-
Policymakers will rely on standardized benchmarks to regulate AI safety and reliability.
The Road Ahead
-
Long-Horizon Benchmarks → Multi-step, time-extended evaluations (e.g., 24-hour agent tasks).
-
Adaptive Testing → Benchmarks that evolve, preventing memorization.
-
Domain-Specific Metrics → Specialized tests for law, healthcare, robotics, etc.
-
Transparency Standards → Shared benchmark results across labs to ensure accountability.